| TPUv7:Google向王者揮拳 CUDA 護城河的終結? Anthropic 簽下1GW+ TPU 採購大單;Meta/SSI/xAI/OAI/Anthro 購買的TPU 越多,節省的GPU 資本支出(Capex)就越多;下一代TPUv8AX 和TPUv8X 將正面對決Vera Rubin。 當今世界最頂尖的兩個模型——Anthropic 的Claude 4.5 Opus 和谷歌的Gemini 3,其絕大部分訓練和推理基礎設施都運行在谷歌的TPU 和亞馬遜的Trainium 上。如今,Google正打破常規,開始直接向多家企業出售實體TPU 硬體。這是Nvidia 統治終結的序章嗎? AI 時代的黎明已至,至關重要的是要理解,AI 驅動的軟體其成本結構與傳統軟體截然不同。晶片微架構和系統架構在這些創新軟體的開發和擴展中扮演著決定性角色。與早期軟體時代開發人員成本佔比較高的情況相比,AI 軟體運作的硬體基礎設施對資本支出(Capex)和營運支出(Opex)——進而對毛利率——有著顯著更大的影響。因此,為了能夠部署AI 軟體,投入大量精力優化AI 基礎架構變得前所未有的關鍵。在基礎設施方面擁有優勢的公司,在部署和擴展AI 應用的能力上也必將佔據高地。 早在2006 年,Google就曾兜售過建造AI 專用基礎設施的概念,但這個問題在2013 年達到了沸點。他們意識到,如果想要以任何規模部署AI,就需要將現有的資料中心數量翻倍。因此,他們開始為TPU 晶片奠定基礎,並於2016 年投入生產。有趣的是,亞馬遜在同一年也意識到需要建造客製化晶片。 2013 年,亞馬遜啟動了Nitro 項目,專注於開發晶片以優化通用CPU 運算和儲存。兩家截然不同的公司針對不同的運算時代和軟體範式,優化了各自的基礎設施路徑。 我們長期以來一直認為,TPU 是世界上用於AI 訓練和推理的最佳系統之一,與「叢林之王」 Nvidia 並駕齊驅。 2.5 年前,我們寫過關於「TPU 霸權」的文章,這一論點已被時間證明是非常正確的。 TPU 的成績不言自明:Gemini 3 是世界上最好的模型之一,且完全在TPU 上訓練。在本報告中,我們將深入探討Google策略的巨大轉變——即適當地將TPU 商業化以供外部客戶使用,使其成為Nvidia 最新且最具威脅的商用晶片(Merchant Silicon)挑戰者。 本報告計劃:
首先,讓我們來談談這則新聞對生態系統的影響。 TPU 的效能顯然引起了競爭對手的注意。 Sam Altman 承認,由於Gemini 搶了OpenAI 的風頭,OpenAI 正面臨「倍感壓力(rough vibes)」的局面。 Nvidia 甚至發布了一份令人寬慰的公關稿,告訴大家保持冷靜並繼續前進——聲稱自己仍遙遙領先競爭對手。
我們理解其中的原因。過去幾個月對Google Deepmind、GCP(Google雲端平台)和TPU 綜合體來說是一個接一個的勝利。 TPU 產量的大幅上調、Anthropic 超過1GW 的TPU 擴建、在TPU 上訓練的SOTA(最先進)模型Gemini 3 和Opus 4.5,以及現在正在擴大的目標客戶名單(Meta、SSI、xAI、OAI)排隊等待TPU。這推動了Google和TPU 供應鏈的巨大價值重估,而代價是Nvidia GPU 供應鏈的損失。雖然Google和TPU 供應鏈的「突然」崛起讓許多人感到驚訝,但SemiAnalysis 的機構產品訂閱者在過去一年中早已預料到了這一點。
(圖表:TPU、Trainium、Nvidia 風險敞口的基礎設施籃子比較) Nvidia 處於守勢的另一個原因是,越來越多的懷疑論者認為該公司正在通過資助燒錢的AI 新創公司來支撐一種“循環經濟”,本質上是用額外的步驟將錢從一個口袋轉移到另一個口袋。我們認為這種觀點是有失偏頗的,但這顯然觸動了Nvidia 內部的神經。財務團隊發布了一份詳細的回應,轉載如下。
我們認為更現實的解釋是,Nvidia 旨在透過提供股權投資而不是降價來保護其在**基礎實驗室(Foundation Labs)**的主導地位,因為降價會降低毛利率並引起廣泛的投資者恐慌。下面,我們概述了OpenAI 和Anthropic 的安排,以展示前沿實驗室如何透過購買或威脅購買TPU 來降低GPU TCO。
(表:你買的TPU 越多,你省下的GPU 費用就越多) 來源:SemiAnalysis TCO 模型,Anthropic 和OpenAI OpenAI 甚至還沒有部署TPU,他們就已經在整個實驗室範圍內的NVIDIA 艦隊上節省了約30%。這證明了TPU 的每TCO 效能優勢是如此強大,以至於你甚至在開啟一台TPU 之前就已經獲得了採用TPU 的收益。 我們的加速器產業模型、資料中心產業模型和核心研究訂閱者在這一消息宣布並成為市場共識之前很久就看到了產業影響。 8 月初,我們與加速器模型客戶分享了我們看到供應鏈中Broadcom / Google TPU 訂單在2026 年的大規模上調。我們也透露,這些訂單增加的原因是Google將開始向多個客戶外部銷售系統。 9 月初,我們透露其中一個大的外部客戶將是Anthropic,需求至少為100 萬個TPU。這在10 月得到了Anthropic 和谷歌的正式確認。我們也在11 月7 日指出Meta 是一個大的TPU 客戶,比其他人早了幾週。此外,我們也討論了其他客戶。 結果,我們的機構客戶對AI 交易中迄今為止最大的**性能分化(Performance Dispersion)**有了充分的預期。 SemiAnalysis 是第一個揭露所有這些見解的公司,因為沒有其他研究公司能夠將從晶圓廠到供應鏈,再透過資料中心到實驗室的點連接起來。 言歸正傳。 谷歌的大規模TPU 外部化推進與Anthropic 交易TPU 堆疊長期以來一直與Nvidia 的AI 硬體相媲美,但它主要支援Google的內部工作負載。按照谷歌的一貫作風,即使在2018 年向GCP 客戶提供TPU 後,它也從未將其完全商業化。這種情況正在開始改變。在過去的幾個月裡,Google動員了整個堆疊的力量,透過GCP 將TPU 帶給外部客戶,或作為商業供應商銷售完整的TPU 系統。這家搜尋巨頭正在利用其強大的內部晶片設計能力,成為真正差異化的雲端供應商。此外,這與旗艦客戶(Marquis Customer) Anthropic 繼續推動擺脫對NVDA 依賴的策略一致。
(圖表:Anthropic FLOP 組合) Anthropic 的交易標誌著這一推進的一個重要里程碑。我們了解到GCP CEO Thomas Kurian 在談判中發揮了核心作用。谷歌很早就承諾積極投資Anthropic 的融資輪次,甚至同意放棄投票權並將所有權上限設定為15%,以將TPU 的使用擴展到谷歌內部之外。前DeepMind TPU 人才在基礎實驗室的存在促進了這項策略的實施,導致Anthropic 在包括TPU 在內的多種硬體上訓練Sonnet 和Opus 4.5。谷歌已經為Anthropic 建立了一個實質性的設施,如下所示,這是我們「逐個建築追蹤AI 實驗室」計畫的一部分。
(圖:資料中心產業模型) 除了透過GCP 租用Google資料中心的容量外,Anthropic 還將在自己的設施中部署TPU,這使Google能夠作為真正的商用硬體供應商直接與Nvidia 競爭。 關於100 萬個TPU 的拆分:
儘管內部和外部需求龐大,但Google未能以其希望的速度部署TPU。儘管與其他仍需「討好」 Jensen(黃仁勳)的超大規模廠商相比,Google對其硬體供應有更多的控制權,但Google的主要瓶頸是電力。 當其他超大規模廠商擴大自己的網站並獲得大量託管容量時,Google的行動較為緩慢。我們認為核心問題是合約和行政方面的。每個新的資料中心供應商都需要一份主服務協議(MSA),這些是數十億美元、多年的承諾,自然涉及一些官僚主義。然而,Google的流程特別緩慢,從最初的討論到簽署MSA 通常需要長達三年的時間。 谷歌的變通方案對尋求轉向AI 資料中心基礎設施的Neocloud 供應商和加密貨幣礦工具有重大影響。谷歌不直接租賃,而是提供信用兜底(credit backstop),即如果Fluidstack 無法支付其數據中心租金,谷歌將介入支付,這是一張資產負債表外的“借條(IOU)”。
(圖表:Fluidstack 交易概覽) 像Fluidstack 這樣的Neocloud 靈活敏捷,使他們更容易與像「轉型後的加密礦工」這樣的新資料中心供應商打交道。這種機制一直是我們看好加密採礦業的關鍵——值得注意的是,我們在今年年初股價大幅降低時就點名了包括IREN 和Applied Digital 在內的眾多公司。 礦工的機會在於一個簡單的動態:資料中心產業面臨嚴重的電力限制,而加密礦工透過其購電協議(PPA)和現有的電力基礎設施已經控制了容量。我們預計未來幾週和幾個季度將有更多協議達成。 谷歌如何重塑Neocloud 市場在Google/Fluidstack/TeraWulf 交易之前,我們在Neocloud 市場從未見過任何僅憑資產負債表外「借據」達成的交易。交易之後,我們認為它已成為新的事實上的標準融資模板。這解決了Neocloud 尋求確保資料中心容量並發展業務的關鍵難題:
這種期限錯配使得Neocloud 和資料中心供應商為專案融資變得非常複雜。但隨著「超大規模廠商兜底」的興起,我們相信融資問題已解決。我們預計Neocloud 產業將迎來新一波成長。查看我們的加速器和資料中心模型以了解主要的受益者。這些是Anthropic 交易背後的方式和原因,現在讓我們進入硬體部分。 此外,擁有Jensen 作為投資者的Neocloud,如CoreWeave、Nebius、Crusoe、Together、Lambda、Firmus 和Nscale,都有明顯的動機不採用其資料中心內的任何競爭技術:TPU、AMD GPU 甚至Arista 交換器都是禁區!這在TPU 託管市場留下了一個巨大的缺口,目前由加密礦工+ Fluidstack 填補。在接下來的幾個月裡,我們預計會看到更多的Neocloud 在追求不斷增長的TPU 託管機會和確保最新最棒的Nvidia Rubin 系統分配之間做出艱難的決定。 TPUv7 Ironwood – 為什麼Anthropic 和其他客戶想要TPU?答案很簡單。這是一個優秀的系統中的強大晶片,這種組合為Anthropic 提供了令人信服的性能和TCO。 2.5 年前,我們寫過一篇關於Google計算基礎設施優勢的文章。即使晶片在紙面上落後於Nvidia,Google的系統級工程也允許TPU 堆疊在性能和成本效率上與Nvidia 匹敵。 我們當時認為“系統比微架構更重要”,過去兩年的情況加強了這一觀點。 Anthropic 的大規模TPU 訂單是對該平台技術實力的直接驗證。 GPU 生態系統也向前邁進了一步。 Nvidia 的GB200 代表了一個巨大的飛躍,推動Nvidia 成為一家真正的系統公司,設計完整的伺服器而不僅僅是內部的晶片封裝。 當我們談論GB200 在機架級互連方面的巨大創新時,一個被低估的點是,自2017 年TPU v2 以來,谷歌一直在機架內和跨機架縱向擴展(Scaling up) TPU!在報告的後面,我們將對Google的ICI 擴展網路進行深入分析,這是Nvidia NVLink 的唯一真正競爭對手。 谷歌最近的Gemini 3 模型現在被視為最先進的前沿LLM。像所有早期版本的Gemini 一樣,它完全在TPU 上訓練。這一結果為TPU 能力和谷歌更廣泛的基礎設施優勢提供了具體證明。 今天的注意力通常集中在推理和後訓練的硬體上,但預訓練前緣模型仍然是AI 硬體中最困難和資源最密集的挑戰。 TPU 平台已經果斷地通過了這項測試。這與競爭對手形成鮮明對比:OpenAI 的領先研究人員自2024 年5 月的GPT-4o 以來尚未完成廣泛用於新前沿模型的成功全規模預訓練運行,突顯了谷歌TPU 艦隊已成功克服的重大技術障礙。 新模型的關鍵亮點包括在工具呼叫和代理能力方面的顯著提升,特別是在具有經濟價值的長期任務上。 Vending Bench 是一項旨在衡量模型在長期內經營業務的能力的評估,透過將它們置於模擬自動販賣機業務的所有者位置,Gemini 3 摧毀了競爭對手。
(圖表:Vending-Bench 資金隨時間變化) 這次發布不僅帶來了能力的提升,也帶來了新產品。 Antigravity,一個源自於收購前Windsurf CEO Varun Mohan 及其團隊的產品,是Google對OpenAI Codex 的回應,正式讓Gemini 進入了「直覺式程式設計(vibe coding)」的代幣消耗戰。 對於谷歌來說,悄悄地介入並在最具挑戰性的硬體問題之一上建立性能領先地位,對於一家核心業務不是——或者我們應該說,曾經不是——硬體業務的公司來說,確實是一個令人印象深刻的壯舉。 微架構仍然很重要:Ironwood 接近Blackwell「系統比微架構更重要」的推論是,雖然Google一直在推動系統和網路設計的邊界,但TPU 晶片本身並不是太具突破性。從那時起,TPU 晶片在最新幾代中取得了巨大進步。 從一開始,Google的設計概念相對於Nvidia 在晶片上就更為保守。歷史上,TPU 的峰值理論FLOPs 明顯較少,記憶體規格也低於對應的Nvidia GPU。 這有3 個原因。首先,谷歌對其基礎設施的「RAS」(可靠性、可用性和可維護性)給予了很高的內部重視。谷歌寧願犧牲絕對性能來換取更高的硬體正常運行時間。將設備運行到極限意味著更高的硬體死亡率,這對系統停機時間和熱備件方面的TCO 有實際影響。畢竟,你無法使用的硬體相對於效能來說具有無限的TCO。 第二個原因是,直到2023 年,Google的主要AI 工作負載是為其核心搜尋和廣告資產提供動力的推薦系統模型。與LLM 工作負載相比,RecSys 工作負載的**算術強度(arithmetic intensity)**要低得多,這意味著相對於傳輸的每一位數據,所需的FLOPs 更少。
(圖表:Reco vs. LLM) 第三點歸結為被行銷的「峰值理論FLOPs」數字的效用以及它們如何被操縱。像Nvidia 和AMD 這樣的商用GPU 供應商希望為其晶片行銷最佳的效能規格。這激勵他們將行銷的FLOPs 拉伸到盡可能高的數字。實際上,這些數字是無法維持的。另一方面,TPU 主要面向內部,在外部誇大這些規格的壓力要小得多。這具有我們將進一步討論的重要意義。客氣的看法是Nvidia 更擅長DVFS(動態電壓頻率調整),因此樂於僅報告峰值規格。 在我們進入LLM 時代後,Google的TPU 設計理念發生了明顯的轉變。我們可以看到,在LLM 之後設計的最新兩代TPU:TPUv6 Trillium (Ghostlite) 和TPUv7 Ironwood (Ghostfish) 反映了這種變化。我們可以在下面的圖表中看到,對於TPUv4 和v5,計算吞吐量遠低於當時的Nvidia 旗艦產品。 TPUv6 在FLOPs 上非常接近H100/H200,但它比H100 晚了2 年。隨著TPU v7 的推出,差距進一步縮小,伺服器僅晚幾季可用,同時提供幾乎相同水準的峰值理論FLOPs。
(圖表:TPU 與Nvidia 的TFLOPs 和系統可用性比較(BF16 Dense)) 是什麼推動了這些效能提升?部分原因是谷歌開始在TPU 投入生產時宣布它們,而不是在下一代部署後宣布。此外,TPU v6 Trillium 採用與TPU v5p 相同的N5 節點製造,矽面積相似,但能夠提供驚人的2 倍峰值理論FLOPs 增加,且功耗顯著降低!對於Trillium,Google將每個**脈動陣列(systolic array)**的大小從128 x 128 增加到256 x 256 tiles,翻了兩番,這種陣列大小的增加帶來了計算能力的提升。
(表格:GoogleTPU 晶片規格) Trillium 也是最後一個「E」(lite)SKU,這意味著它僅配備了2 個HBM3 站點。雖然Trillium 在計算上縮小了與Hopper 的差距,但在記憶體容量和頻寬上遠低於H100/H200,僅有2 個堆疊HBM3,而後者分別為5 和6 堆疊HBM3 和HBM3E。這使得新手使用起來很痛苦,但如果你正確地對模型進行**分片(shard)**並利用所有那些廉價的FLOPS,Trillium 實現的性能TCO 是無與倫比的。
(圖表:TPU v6 (Trillium) vs H100 (SXM) 比較) TPU v7 Ironwood 是下一個迭代,Google在FLOPs、記憶體和頻寬方面幾乎完全縮小了與相應Nvidia 旗艦GPU 的差距,儘管全面上市時間比Blackwell 晚1 年。與GB200 相比,FLOPs 和記憶體頻寬僅有輕微的短缺,容量與8-Hi HBM3E 相同,當然這與擁有288GB 12-Hi HBM3E 的GB300 相比有顯著差距。
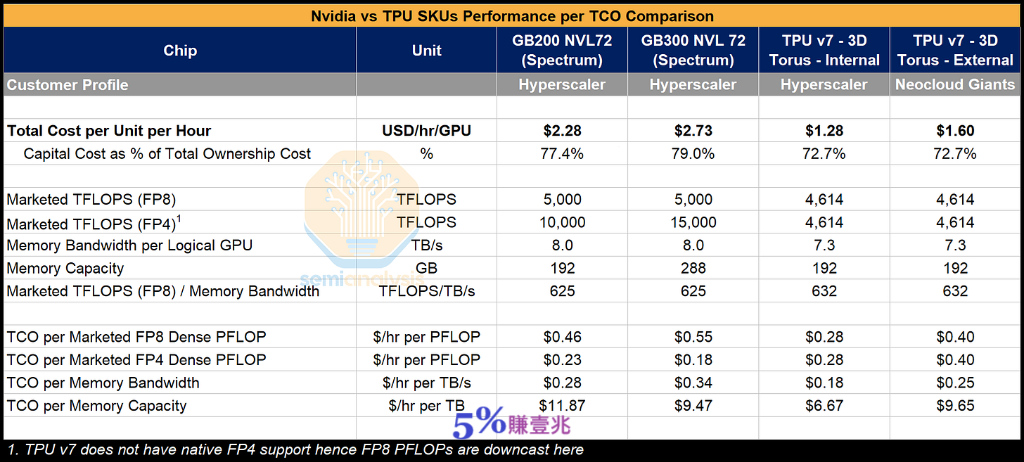
(圖表:TPU v7 (Ironwood) vs GB200/GB300 比較) 理論絕對性能是一回事,但真正重要的是每總擁有成本(TCO) 的真實世界性能。 雖然Google透過Broadcom 採購TPU 並支付高額利潤,但這遠低於Nvidia 不僅在銷售GPU 上,而且在包括CPU、交換器、NIC、系統記憶體、佈線和連接器在內的整個系統上賺取的利潤。從Google的角度來看,這導致全3D 環面(3D Torus)配置的每Ironwood 晶片的全包TCO比GB200 伺服器的TCO 低約44%。 這足以彌補峰值FLOPs 和峰值記憶體頻寬約10% 的短缺。這是從Google的角度以及他們採購TPU 伺服器的價格來看的。
(表格:Nvidia vs TPU SKU 每TCO 效能比較) 那麼當谷歌加上他們的利潤後,對外部客戶來說呢?我們假設在Google向外部客戶租賃TPU 7 賺取利潤的情況下,每小時TCO 仍然可以比GB200 的成本低約30%,比GB300 的成本低約41%。我們認為這反映了Anthropic 透過GCP 的定價。
(圖表:每小時總成本比較(USD/hr/GPU)) 為什麼Anthropic 押注TPU比較理論FLOPs 只能說明部分情況。重要的是有效FLOPs,因為尖峰數字在實際工作負載中幾乎從未達到。 實際上,一旦考慮到通訊開銷、記憶體停頓、功率限制和其他系統效應,Nvidia GPU 通常只能達到其理論峰值的一小部分。訓練的一個經驗法則是30%,但利用率也因工作負載而異。差距的很大一部分歸結為軟體和編譯器效率。 Nvidia 在這方面的優勢源自於CUDA 護城河和開箱即用的廣泛開源庫,幫助工作負載高效運行,實現高FLOPs 和記憶體頻寬利用率。 TPU 軟體堆疊並不那麼容易使用,儘管這正在開始改變。在Google內部,TPU 受益於優秀的內部工具,這些工具不對外部客戶開放,這使得開箱即用的效能較弱。然而,這只適用於小型和/或懶惰的用戶,而Anthropic 兩者都不是。 Anthropic 擁有強大的工程資源和前Google編譯器專家,他們既了解TPU 堆疊,也深入了解自己的模型架構。他們可以投資定制核心以推動高TPU 效率。結果,他們可以達到大幅更高的MFU 和更好的每PFLOP 性能價格比。 我們相信,儘管行銷的峰值FLOPs 較低,TPU 可以達到比Blackwell 更高的已實現模型FLOP 利用率(MFU),這意味著Ironwood 的有效FLOPs 更高。一個主要原因是Nvidia 和AMD 行銷的GPU FLOPs 明顯被誇大了。即使在旨在通過GEMM 最大化吞吐量的測試中(形狀遠非實際工作負載),Hopper 僅達到峰值的約80%,Blackwell 落在70% 左右,而AMD 的MI300 系列在50%-60% 之間。 限制因素是電力傳輸。這些晶片無法維持峰值數學運算中使用的時脈速度。 Nvidia 和AMD 實作動態電壓和頻率縮放(DVFS),這意味著晶片的時脈頻率根據功耗和熱量動態調整,而不是可以實際維持的穩定時脈頻率。 Nvidia 和AMD 然後選擇可能交付的最高時脈頻率(即使是非常間歇性的)用於計算峰值理論FLOPs(每個週期的操作數/ALU x ALU 數量x 每秒週期數,即時脈頻率)。 還有其他技巧被使用,例如在零填充張量(zero-filled tensors)上運行GEMM,因為0x0=0,晶體管不需要從0 切換到1,從而降低了每次操作的功耗。當然,在現實世界中,零填充張量不會相乘。 當我們結合低得多的TCO 和更高的有效FLOPs 使用率時,從Google的角度來看,每有效FLOP 的美元成本變得便宜得多,約15% 的MFU 是與30% MFU 的GB300 的損益平衡點。這意味著如果谷歌(或Anthropic)設法達到GB300 FLOPs 利用率的一半,他們仍然能打平。當然,憑藉Google的精英編譯器工程師團隊和對自己模型的深刻理解,他們在TPU 上實現的MFU 可能達到40%。那將是每有效訓練FLOP 成本驚人的約62% 的降低!
(圖表:不同MFU 下的TCO / 有效訓練Dense FP8 PFLOP ($/hr per Eff PFLOP)) 然而,當觀察60 萬個租賃的TPU 時,當我們將Anthropic 支付的較高TCO(即包括谷歌的利潤疊加)納入此分析時,我們估計Anthropic 從GCP 獲得的成本為每TPU 小時1.60 美元,縮小了TCO 優勢。我們相信Anthropic 可以在TPU 上實現40% 的MFU,這歸功於他們對效能優化的關注以及TPU 行銷的FLOPs 本質上更現實。這為Anthropic 提供了比GB300 NVL72 低驚人的約52% 的每有效PFLOP TCO。與GB300 基準相比,每有效FLOP TCO 相同的平衡點在於Anthropic 擷取的MFU 低至19%。這意味著Anthropic 可以承受相對於基準GB300 相當大的效能短缺,而訓練FLOPs 的效能/TCO 最終仍與基準Nvidia 系統相同。
(圖表:不同MFU 下的TCO / 有效訓練Dense FP8 PFLOP) FLOPs 並不是效能的全部,記憶體頻寬對於推理非常重要,特別是在頻寬密集的解碼步驟中。毫不奇怪,TPU 的每記憶體頻寬美元成本也比GB300 便宜得多。有重要證據表明,在小消息大小(如16MB 到64MB,加載單層的專家)下,TPU 甚至實現了比GPU 更高的記憶體頻寬利用率。
(圖表:TCO / 記憶體頻寬($/hr per TB/s)) 所有這些都轉化為訓練和服務模型的高效計算。 Anthropic 發布的Opus 4.5 繼續其一貫的編碼重點,創下了新的SWE-Bench 記錄。主要的驚喜是API 價格降低了約67%。這種降價加上模型比Sonnet 更低的冗餘度和更高的代幣效率(達到Sonnet 最佳分數所需的代幣減少76%,超過其4 分所需的代幣減少45%),意味著Opus 4.5 是編碼用例的最佳模型,並且可以有效地提高Anthropic 的實際token組合,因為Sonnet 目前佔代幣組合的定價,因為Sonnet90% 以上的定價。
(圖表:Anthropic API 定價)
(圖表:SWE-Bench 分數vs 所需總輸出Tokens) 谷歌在利潤率上穿針引線
最新評論 |